

When submitting a scientific paper to a conference or a journal, there is often a mandatory step of passing the automated PDF checks set up by that publication. This step can often be nerve-racking and cause many hours of LaTeX troubleshooting. In this post we will create a series of test cases to catch these problems early in the writing process so that you can submit your manuscript only once.
Introduction
Recently, I submitted a scientific paper to an IEEE conference. For a manuscript to be accepted by the publishing system Editor's Assistant (EDAS) it has to pass an unknown number of unspecified test cases. This took far too many attempts, as can be seen in the figure to the right.
Here is one error that I received.
The gutter between columns is 0.165 inches wide (on page 3), but should be at least 0.2 inches.
Nowhere did it say that the gutter should be 0.2 inches. Another IEEE conference that I submitted to had a smallest gutter width of 0.16 inches, and it seems that this is up to each conference chair to decide. As you can imagine, when trying to fix this, some text will spill over to the next page so then the document is over the page-limit. Uploading a document many times is a pain.
In this post we will create a series of test cases to catch these errors locally before submitting.
The publishing system gave this message for the final version of the manuscript that was uploaded without problems.
The paper has 6 pages, has a paper size of 8.5x11 in (letter), is formatted in 2 columns, with a gutter of 0.201 inches (smallest on pg. 5), the most common font size is 9.96 pt, the average line spacing is 11.95 pt, margins are 0.673 (L) x 0.653 (R) x 0.701 (T) x 0.990 (B) inches, uses PDF version 1.7 and was created by TeX.
Template
The techniques we use here can of course be applied to any PDF document. We will here take a look at a two-column conference paper since this provides us with a number of interesting things to test that other formats don’t.

The IEEE Manuscript Templates for Conference Proceedings example is particularly interesting due to the multiple author bounding boxes. We can download the template and an example document and compile it directly to produce the PDF that we will run our test cases on.
Test cases
Requirements and setup
We need to understand the requirements of the publishing system. Some of these requirements can be found on the conference website. For example, we see that the page limit is 6 pages in a 10 point font, and that we should use the IEEE Manuscript Templates for Conference Proceedings template. Other than that, there is no more useful information.
Here are the requirements, gathered from various sources, that we are going to write test cases for in this post.
| Requirement | Value | Source |
|---|---|---|
| Annotations | no | Obvious |
| Bookmarks | no | EDAS FAQ |
| Encrypted | no | Obvious |
| Font size | 10 pt | Conference CFP, (Shell, 2002) |
| Font type | no PS Type 3 fonts | Hearsay |
| Fonts embedded | embedded | EDAS FAQ |
| Language | English | Conference CFP |
| Links | no | EDAS FAQ |
| Maximum file size | 40 MB | Hearsay |
| Metadata | per taste | |
| Minimum bottom margin | 1 in | IEEE allowed paper sizes |
| Minimum gutter width | 0.16 in | EDAS fault |
| Minimum left/right margin | 0.625 in | IEEE allowed paper sizes |
| Minimum top margin | 0.65 in | IEEE allowed paper sizes, (Shell, 2002) |
| Number of columns | 2 | IEEE Manuscript Templates, (Shell, 2002) |
| Number of pages | 1 <= x <= 6 | Conference CFP |
| Papersize | Letter (612 pt x 792 pt) | (Shell, 2002) |
| PDF version | x > 1.4 | EDAS FAQ |
| Title | Title Case | EDAS FAQ |
Some of them, for example the margins are tweaked after a paper that passed the test had margins narrower than the one suggested by the IEEE requirements.
Test framework
For the test framework we will use the popular Python test framework pytest (Krekel et al., 2004) with the PyMyPdf (McKie & Liu, 2020) package to interact with the PDF file. The entire script can be found in the Gitlab repository How to beat publisher checks with LaTeX document unit testing.
We setup our requirements from the table above as follows in config.yml,
in YAML format.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
metadata:
creator: "TeX"
producer: "pdfTeX-1.40.21"
encryption: null
min_version: 1.4
margins:
min_gutter: 0.16 # in
min_lr_margin: 0.625 # in
min_top_margin: 0.65 # in
min_bottom_margin: 1 # in
pages:
min_pages: 1
max_pages: 6
papersize: [0.0, 0.0, 612.0, 792.0] # Letter, pts
max_file_size: 41943040 # 40 MB
skip_boxes_on_first_page: 12 # test this
required_text: []
Annotations
It would be a bit embarrassing to submit a file with annotations still in it, so let’s start by checking that we didn’t add any.
1
2
3
4
5
6
7
8
def test_annotations(pdf_document):
"""
Test that there are no annotations.
"""
for page1 in pdf_document:
annotations = list(page1.annots())
assert not annotations
Metadata
For the metadata fields creator, producer, author, title, subject,
encryption and keywords we can simply check that the result is as expected by
comparing to what we defined in the configuration file config.yml.
1
2
3
4
5
6
7
8
9
10
11
12
13
def test_metadata(pdf_document, config):
"""
For each of the specified fields, check that the result
is as expected.
"""
metadata_fields = ["author", "creator", "title",
"subject", "keywords", "producer",
"encryption"]
for field in metadata_fields:
assert pdf_document.metadata.get(
field, None) == config["metadata"].get(field, None)
For the PDF version, we usually specify a minimum version so we define a
separate test case for that. Should we need to change this in the document, we
can add
\pdfminorversion=7
to our preamble.
1
2
3
4
5
6
7
8
def test_pdf_version(pdf_document, config):
"""
Test that the PDF version is at least the specified
"""
version = float(pdf_document.metadata.get("format", None).split(" ")[1])
assert version >= config.get("min_version", 1.4)
Number of pages
It is quite common that a conference and a journal has a maximum number of pages. The lowest number of pages is of course one, but we’d most likely want to use every inch of space available to us.
1
2
3
4
5
6
7
8
9
def test_pages(pdf_document, config):
"""
Test that the number of pages is between
the minimum and the maximum number of pages.
"""
assert config.get("min_pages", 1) <= \
pdf_document.pageCount <= \
config.get("max_pages", 5)
Dimensions
To calculate margins and other dimensions it will be required to find the dimensions of each page and each bounding box within each page. In the process we also find the number of columns.
The basic algorithm is as follows: We first loop through each page and each
bounding box within that page. For every bounding box we add an interval to
an interval tree -
one for the dimensions in the x-direction, and one for the dimensions in the
y-direction. For this we will use the Python package
intervaltree
(Leib Halbert & Tretyakov, 2018).
Interval trees (contributors, 2020) are interesting in their own right, but we won’t go into the details of how they work. Here it is enough to say that we can do operations on these interval trees to find the widths of gutters and margins easily.
For each new bounding box we find, we add the interval between the left edge and the right edge to one interval tree. After we have done this for all bounding boxes we merge the overlap of these intervals so that we are left with a list of non-overlapping intervals. We do this both for the x-dimension (illustrated below in blue) and the y-dimension (illustrated below in red).
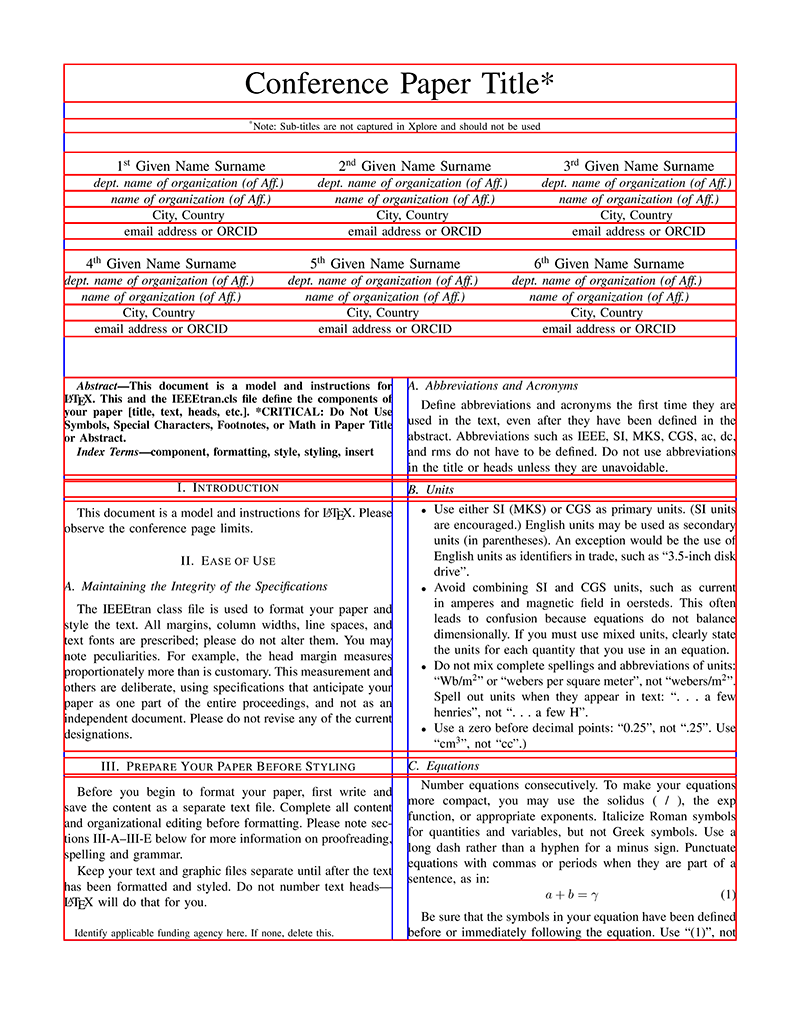

We see that the first page contains things like the title and author blocks that straddle the gutter. This will affect how we can detect the columns and calculate the width of the gutter. Here, we take an easy way out and just skip the first 12 bounding boxes. We find the number of bounding boxes to skip by counting the red boxes in the figure. This problem also extends to pages where a top figure spans the two columns.
After we have calculated the non-overlapping intervals we can easily calculate the width of these. For a two column document, the first interval is the left margin, the second is the first column and the third interval is the gutter. Since the margin and gutter is different on each page, we assert that all of them meet the requiements.
Should the gutter be too narrow (something that always happens way too often) we can tweak the column separation with
1
\setlength{\columnsep}{0.235in}
Another thing that will effect this is microtype and it’s various options,
for example protrusion.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
def test_dimensions(pdf_document, config):
"""
This test case loops through pages and checks
- paper size
- gutter width
- number of columns
Finally it saves a document with the found columns and bounding boxes
overlayed.
"""
blue = (0, 0, 1)
count = 0
for page1 in pdf_document:
full_tree_x = IntervalTree()
full_tree_y = IntervalTree()
tree_x = IntervalTree()
tree_y = IntervalTree()
blks = page1.getTextBlocks() # Read text blocks of input page
img = page1.newShape() # Prepare contents object
# Calculate CropBox & displacement
disp = fitz.Rect(page1.CropBoxPosition, page1.CropBoxPosition)
croprect = page1.rect + disp
full_tree_x.add(Interval(croprect[0], croprect[2]))
full_tree_y.add(Interval(croprect[1], croprect[3]))
# This tests paper size
assert list(croprect) == config["pages"].get("papersize")
for b in blks: # loop through the blocks
r = fitz.Rect(b[:4]) # block rectangle
# add dislacement of original /CropBox
r += disp
x0, y0, x1, y1 = r
# Dangerous!
if count > config.get("skip_boxes_on_first_page", 2):
tree_x.add(Interval(x0, x1))
tree_y.add(Interval(y0, y1))
count += 1
tree_x.merge_overlaps()
tree_y.merge_overlaps()
# Must be two columns
assert len(tree_x) == 2
for intrv in tree_x:
a = [intrv[0], tree_y.begin(), intrv[1], tree_y.end()]
re = fitz.Rect(a)
img.drawRect(re)
img.finish(width=1, color=blue)
img.commit(overlay=True) # store /Contents of out page
for i in tree_x:
full_tree_x.add(i)
full_tree_x.split_overlaps()
for i in tree_y:
full_tree_y.add(i)
full_tree_y.split_overlaps()
# If there are two columns, the gutter should be in the middle.
# Margins are the first and last intervals, the ignored parts
# are the left and right columns.
left_margin, _, gutter, _, right_margin = \
map(get_interval_width, list(sorted(full_tree_x)))
# For top and bottom margins, we only know they are the first and
# last elements in the list
full_tree_y_list = list(sorted(full_tree_y))
top_margin, bottom_margin = \
map(
get_interval_width,
full_tree_y_list[::len(full_tree_y_list) - 1]
)
assert gutter > config["margins"].get("min_gutter", 0.2)
assert left_margin > config["margins"].get("min_lr_margin", 0.625)
assert right_margin > config["margins"].get("min_lr_margin", 0.625)
assert top_margin > config["margins"].get("min_top_margin", 0.75)
assert bottom_margin > config["margins"].get("min_bottom_margin", 1)
# save output file
pdf_document.save("layout.pdf",
garbage=4, deflate=True, clean=True)
Links and bookmarks
Links and bookmarks are created by hyperref. I’d like to keep this package, but set the output to draft for the final publication in order to disable it.
1
2
3
4
\usepackage[
final,
bookmarks=true
]{hyperref}
Testing that we have not links or bookmarks in our document is simple, we just make sure that the list of links on each page is empty and that the bookmark list is empty.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
def test_no_links(pdf_document):
"""
Test that no links appear on any page.
"""
for page1 in pdf_document:
assert len(page1.getLinks()) == 0
def test_no_bookmarks(pdf_document):
"""
Test that the document does not contain bookmarks
"""
assert len(pdf_document.getToC()) == 0
File size
The system that we upload our document to has a limit on the size of document, and it is easy to test for this.
1
2
3
4
5
6
def test_file_size(pdf, config):
"""
Test that the filesize is below the limit.
"""
assert Path(pdf).stat().st_size < config.get("max_file_size", 0)
Spelling and grammar
To test spelling and grammar I use LanguageTool, textidote and vale. However, the number of false positives are staggering and they are unusable for automatic testing. This is also a larger topic that deserves an in-depth analysis.
Title in title case
The title shall be in title case. In this regard EDAS follows the Associated Press Stylebook and the New York Times style book. These state that only short prepositions and articles with four letters or less are lowercase.
The Python package titlecase uses a wordlist from New York Times Manual of Style to decide what words shall be lowercase.
1
2
3
4
5
6
7
8
9
def test_title_case(pdf_document):
"""
Test that the title (first block on first page)
is title cased properly.
"""
page1 = pdf_document.loadPage(0)
title = page1.getTextBlocks()[0][4]
assert title == titlecase(title)
Required text
For my work I am required to put in a pre-defined sentence in the acknowledgment-section so I want to test that the document contains this string. This test case can easily be modified to detect black-listed words.
1
2
3
4
5
6
7
8
9
10
11
def test_required_text(pdf_document, config):
"""
Test that each required text is found in the document.
"""
for text in config.get("required_text", []):
hits = 0
for page1 in pdf_document:
hits += len(page1.getTextPage().search(text))
assert hits > 0
Embedded fonts
We can test that the fonts are embedded by trying to extract them from each page.
This can be optimized since each font will be extracted several times. At the same time
we will check that the font is not a
Postscript Type 3 font, since these can be
bitmap fonts. This can for example happen when using matplotlib since
matplotlib will use Type 3 fonts per default. See (Oaks, 2014) or
Publication ready figures
for ways to get around this.
1
2
3
4
5
6
7
8
9
10
11
def test_embedded_fonts(pdf_document):
"""
Check that all fonts are extractable. This will at least loop through
the embedded fonts and check their types.
"""
for page in pdf_document:
for f in page.getFontList():
_, ext, fonttype, _ = pdf_document.extractFont(f[0])
assert fonttype in ["TrueType", "Type1"]
assert ext != "n/a"
Results of the test cases
We can compile the example document and run our test suite with
1
2
make -C example dist-clean compile
pytest -v --pdf example/Conference-LaTeX-template_10-17-19/conference_101719.pdf
This is the same as running make render test (using Docker containers),
which gives us these results.
1
2
3
4
5
6
7
8
9
10
11
test_pdf.py::test_annotations PASSED [ 9%]
test_pdf.py::test_required_text PASSED [ 18%]
test_pdf.py::test_title_case PASSED [ 27%]
test_pdf.py::test_no_links PASSED [ 36%]
test_pdf.py::test_no_bookmarks PASSED [ 45%]
test_pdf.py::test_file_size PASSED [ 54%]
test_pdf.py::test_pages PASSED [ 63%]
test_pdf.py::test_pdf_version PASSED [ 72%]
test_pdf.py::test_metadata PASSED [ 81%]
test_pdf.py::test_embedded_fonts PASSED [ 90%]
test_pdf.py::test_dimensions PASSED [100%]
Related work
There are many test frameworks and PDF readers that could have been used instead
of pytest and pyMuPDF. In the past I have used rspec with pdf/reader
which is easy to get started with, but since I am more familiar with Python I
opted for that when it came to more advanced tests.
The IEEE Xpress PDF checks or The IEEE LaTeX Analyzer from the IEEE author center do not help us here, since a conference chair can specify other requirements in EDAS that are not checked by these tools.
Discussion
Tests not implemented
There are a few common mistakes that we didn’t create test cases for. The required font sizes is listed by (Shell, 2002), but hard to test for since figures and titles can have wildly different font sizes. Line-spacing is similar to font-size in this regard.
Other common mistakes, such as not referencing a figure in the text is better
suited for linting tools such as textidote.
Conclusions
In this post we have implemented a few test cases to detect common mistakes in IEEE conference submission - before the conference PDF checker catches them. I hope that this saves you some frustration, and some time.
References
- Shell, M. (2002). How to use the IEEEtran LATEX class. Journal of LaTeX Class Files, 12.
- Krekel, H., Oliveira, B., Pfannschmidt, R., Bruynooghe, F., Laugher, B., & Bruhin, F. (2004). pytest. https://github.com/pytest-dev/pytest
- McKie, J. X., & Liu, R. (2020). PyMuPDF. Github. https://github.com/pymupdf/PyMuPDF
- Leib Halbert, C., & Tretyakov, K. (2018). intervaltree. https://pypi.org/project/intervaltree/
- contributors, W. (2020). Interval tree — Wikipedia, The Free Encyclopedia. https://en.wikipedia.org/w/index.php?title=Interval_tree&oldid=956136582
- Oaks, J. (2014). Avoiding Type 3 fonts in matplotlib plots. http://phyletica.org/matplotlib-fonts/
Suggested citation
If you would like to cite this work, here is a suggested citation in BibTeX format.
@misc{isaksson_2020,
author="Isaksson, Martin",
title={{Martin's blog --- How to beat publisher PDF checks with LaTeX document unit testing}},
year=2020,
url=https://blog.martisak.se/2020/05/16/latex-test-cases/,
note = "[Online; accessed 2026-07-12]"
}